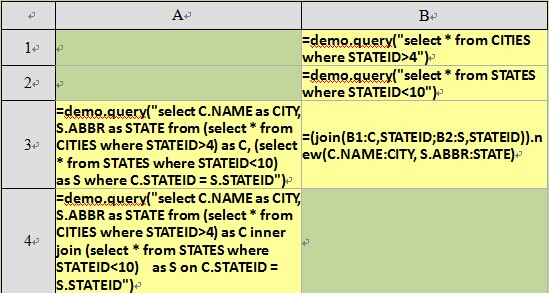
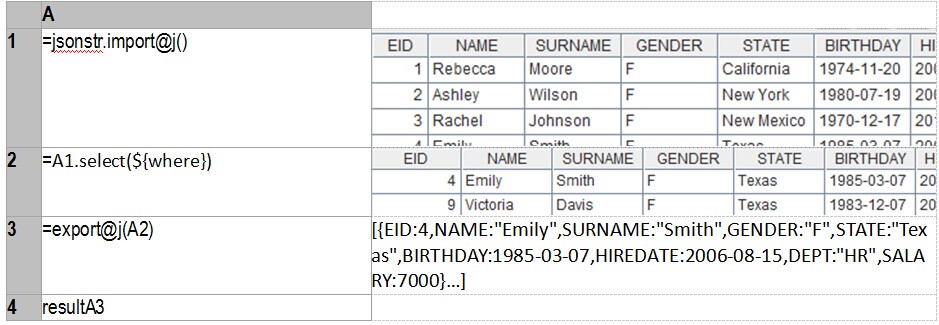
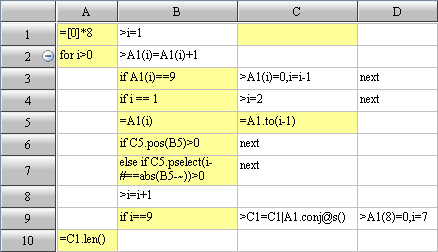
1 What OLAP We Need In Deed?
Category: Model
OLAP is an important constituent part of BI(business intelligence).
Understood literally, OLAP is online analytical processing, that is, users conduct analytical operation on real-time business data.
But, currently the concept of OLAP is seriously narrowed, and only it refers to operations such as conducting drilling, aggregating, pivoting and slicing based on multi-dimensional data, namely, multi-dimensional interaction analysis.
To apply this kind of OLAP, it is necessary to create in advance a group of topic specific data CUBEs. Then users can display these data in the form of crosstab or graph and conduct in various real-time transformations (pivoting and drilling) on them, in the hope to find in the transformation process a certain law of the data or the argument to support a certain conclusion, thereby achieving the aim of analysis.
Is this kind of OLAP we need?
To answer this question, we need to carefully investigate the real application process of the OLAP, thereby finding out what the technical problem the OLAP needs to solve is on earth.
Employees with years’ working experiences in any industry generally have some educated guesses about the businesses they engage in, such as:
A stock analyst may guess stocks meeting a certain condition are likely to go up.
An employee of an airline company may guess what kinds of people are accustomed to buying what kind of flights.
A supermarket operator may also guess the commodity at what price is more suitable for the people around the supermarket.
…
These guesses are just the basis for forecast. After operating for a period of time, a constructed business system can also accumulate large quantities of data, and these guesses have most probably been evaluated by these accumulated data, when evaluated to be true, they can be used in forecast; when evaluated to be false they will be re-guessed.
It needs to be noted that these guesses are made by users themselves instead of the computer system! What a computer should do is to help a user to evaluate, according to the existing data, the guess to be true or false, namely, on-line data query (including certain aggregation computation). This is just the application process of OLAP. The reason why on-line analysis is needed is that many query computations are temporarily required after a user has seen a certain intermediate result. In the whole process, model in advance is impossible and unnecessary.
We call the above process evaluation process, whose purpose is to find from historical data some laws or evidences for conclusions, and the means adopted is to conduct interactive query computation on historical data.
The following are a few examples actually requiring computations (or queries):
The first n customers whose purchases from the company account for half of the sales volume of the company of the current year;
The stocks which go up to the limit for three consecutive days within one month;
Commodities in the supermarket which are sold out at 5 P.M for three times within one month;
Commodities whose sales volumes in this month have decreased by more than 20% over those of the preceding month;
…
Evidently, this type of computation demand is ubiquitous in business analysis process and all can be computed out from historical database.
Then, can the narrowed OLAP be used to complete the above-mentioned computation process?
Of course NOT!
Currently OLAP system has two key disadvantages:
- 1. The multi-dimensional cube is prepared in advance by the application system and user does not have the capability to temporarily design or reconstruct the cube, so once there is new analysis demand, it is necessary to re-create the cube.
- 2. The analysis actions could be implemented by cube are rather monotonous. The defined actions are quite few, such as the drilling, aggregating, slicing, and pivoting. The complicated analysis behavior requiring multi-steps is hard to implement.
Although the current OLAP products are splendid regarding its look and feel, few on-line analysis capabilities powerful enough are provided actually.
Then, what kind of OLAP do we need?
It is very simple, and we need a kind of on-line analytical system that can support evaluation process!
Technically speaking, steps for evaluation process can be regarded as computation regarding data (query can be understood to be filter computation). This kind of computation can be freely defined by user and user can occasionally decide the next computation action according to the existing intermediate result, without having to model beforehand. Additionally, as data source is generally database system, it is necessary to require this kind of computation to be able to very well support mass structured data instead of simple numeric computation.
Then, can SQL (or MDX) play this role?
SQL is indeed invented for this aim and it owns complete computation capability and it adopts a writing style similar to natural language.
But, as SQL computation system is too basic, it is very difficult and over-elaborate to use it to achieve complex computation, such as problems listed in the preceding paragraphs. It is even not so easy for programmers who have received professional training, so ordinary users can only use SQL to implement some of the simplest queries and aggregate computation (based on the filter and summarization of a single table). This result leads to the fact that the application of SQL has already deviated far away from its original intention of invention, almost becoming the expertise for programmers.
We should follow the working thought of SQL to carefully study the specific disadvantage of SQL and find the way to overcome it in an effort to develop a new generation of computation system, thereby implementing the evaluation process, namely, the real OLAP.
2 The Disadvantages of SQL Computation
Category: Model
SQL is invented primarily to provide a method to access structured data in order to transparentise the physical storage scheme, so a lot of various types of English vocabularies and syntaxes are used in SQL to reduce the difficulty in understanding and writing it. And the relational algebra as the basic theory of SQL is a complete computation system, which can compute everything in principle. In terms of this, we certainly should use SQL to satisfy various demands for data computation.
But, though relational database has achieved a huge success, evidently SQL fails to realize its original aim of invention. Except very few simple queries can be completed by end user using SQL, most of SQL users are still technical personnel, and even many complex queries are no easy job for technical personnel.
Why? We inspect the disadvantage of SQL in computation through a very simple example.
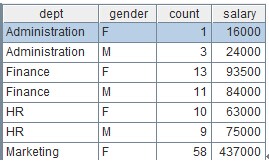
Suppose there is a sales performance table consisting of three fields (to simplify the problem, date information is omitted):
sales_amount | Sales performance table |
sales | Name of salesman, suppose there is no duplicate name. |
product | Products sold |
amount | Sales amount of the salesman on the product |
Now we want to know the name list of the salespersons whose sales amounts rank among the top 10 places both in air-conditioners and TV sets.
This question is rather simple and people will very naturally design out the computation process as follows:
- Arrange the sequence according to the sales amount of air-conditioner and find out the top 10 places.
- Arrange the sequence according to the sales amount of TV and find out the top 10 places.
- Get the intersection of the results of 1 and 2 and obtain the answer.
Now we use SQL to do it.
- Find out the top 10 places of the sales amount of air-conditioner. This is very simple:
select top 10 sales from sales_amount where product='AC' order by amount desc
- Find out the top 10 places of the sales amount of TV. The action is the same:
select top 10 sales from sales_amount where product='TV' order by amount desc
- Seek the intersection of 1 and 2. This is somewhat troublesome, as SQL does not support computation by steps. The computation result of the above two steps cannot be saved, and thus it is necessary to copy it once again:
select * from
( select top 10 sales from sales_amount where product='AC' order by amount desc )
intersect
( select top 10 sales from sales_amount where product='TV' order by amount desc )
A simple 3-step computation has to be written like this using SQL, and daily computations of more than 10 steps are in great numbers. So this evidently goes beyond the acceptability of many people.
In this way, we know the first important disadvantage of SQL: Do not support computation by steps. Dividing complex computation into several steps can reduce the difficulty of a problem to a great extent. On the contrary, completing many steps of computation into one step can increase the difficulty of a problem to a great extent.
It can be imagined that, if a teacher requires pupils to create only one calculation formula to complete the calculation in solving application problems, how distressed the pupils will feel (of course, there are certain clever children who can solve the problem)!
SQL query cannot by conducted by steps, but the stored procedure written out with SQL can operate by steps. Then, is it possible to use the stored procedure to conveniently solve this problem?
For the time being, we just ignore how complex is the technical environment in which the stored procedure is used (this is enough to make most people give it up) and the incompatibility caused by differences of databases. We only try to know theoretically whether it is possible to use SQL to make this computation simpler and faster.
- Compute the top 10 places sales amount of air-conditioners. The statement is still the same, but we need to save the result for use by Step 3, while in SQL, it is only possible to use table to store set data. So we need to create a temporary table:
create temporary table x1 as
select top 10 sales from sales_amount where product='AC' order by amount desc
- Compute the top 10 places of the sales amount of TV. Similarly
create temporary table x2 as
select top 10 sales from sales_amount where product='TV' order by amount desc
- Seek the intersection, the preceding steps are troublesome but this step is simpler.
select * from x1 intersect x2
After the computation is done in steps, the working thought becomes clear, but it still appears over-elaborate to use a temporary table. In the computation of mass structured data, temporary set, as intermediate result, is rather common. If the temporary table is created for storage in all cases, the computation efficiency is low and it is not intuitive.
Moreover, SQL does not allow the value of a certain field to be a set (namely temporary table), so in this way, it is impossible to implement some computations even if we tolerate the over elaborate.
If we change the problem into computing the salespersons whose sales amounts of all products rank among the top 10 places, try thinking how to compute it. By continuing to use the above-mentioned working thought, it is very easy to get the below points:
- Group the data according to products, arrange the sequence of each group, and get the top 10 places;
- Get the intersection of the top 10 places of all products;
As we do not know beforehand how many products there are, so it is necessary to also store the grouping result in a temporary table. There is a field in this table that needs to store the corresponding group members, which is not supported by SQL, so the method is unfeasible.
If supported by window function (SQL2003 standard), it is possible to change the working thought. After grouping by product, compute the number of times each salesman appears in the top 10 places of the sales amounts of all product category group. If the number of times is the same as the total number of the product categories, it indicates this salesman is within the top 10 places regarding the sales amounts of all product categories.
select sales
from ( select sales,
from ( select sales,
rank() over (partition by product order by amount desc ) ranking
from sales_amount)
where ranking <=10 )
group by sales
having count(*)=(select count(distinct product) from sales_amount)
How many people can write such complex SQL?
Moreover, in many databases, the window functions are not supported. Then, it is only possible to use the stored procedure to develop a loop, according to the sequence, the top 10 places of each product, and seek the intersection of the result of the preceding time. This process is not very much simpler than using high level language to develop, and it is also necessary to cope with the triviality of the temporary table.
Now, we know the second important disadvantage of SQL: Set-lization is not complete. Though SQL has the concept of set, it fails to provide set as a kind of basic data type, which makes it necessary to transform a lot of natural set computations in thinking and writing.
In the above computation, we have used the keyword top. In fact there is not such a thing (it can be combined out by other computation computations) in the theory of relational algebra, and this is not the standard writing style of SQL.
Let us see how difficult it is to look for the top 10 places when there is no top.
Rough working thought: Seek out the number of members whose sales amount are higher than itself to rank the sales person, and then get the members whose places do not exceed 10, and the SQL is written as follows:
select sales
from ( select A.sales sales, A.product product,
(select count(*)+1 from sales_amount
where A.product=product AND A.amount<=amount) ranking
from sales_amount A )
where product='AC' AND ranking<=10
or
select sales
from ( select A.sales sales, A.product product, count(*)+1 ranking
from sales_amount A, sales_amount B
where A.sales=B.sales and A.product=B.product AND A.amount<=B.amount
group by A.sales,A.product )
where product='AC' AND ranking<=10
Professional technical personnel may not necessarily write such SQL statement well! And only the first ten places are computed.
To say the least, even if there is top, it only makes it easy to get the preceding part lightly. If we change the problem into getting the 6th place to the 10th place, or seeking the salesman whose sales amount is 10% more than that of the next one, the difficulty is still there.
The reason causing this phenomenon lies in the third important disadvantage of SQL: Lack the support of ordered set. SQL inherits the unordered set in mathematics, which directly causes the fact that the computations relating to sequence are rather difficult. And it can be imagined how common the computations relating to sequence (such as over the preceding month, over the same period last year, the first 20%, and rankings) will be.
The newly added window functions in SQL2003 standard provides some computation capabilities relating to sequence, which makes it possible to solve some problems in a relatively simple method and alleviate the problem of SQL to a certain extent. But the use of window functions is often accompanied by sub-query, and it cannot enable user to directly use the sequence number to access set member, so there are still many ordered computations that are difficult to solve.
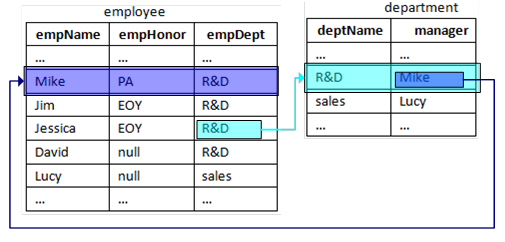
Now we want to pay attention to the gender proportion of the “good” salespersons that are computed out, that is, how many males and females there are respectively. Generally, the gender information is recorded in the employee table but not in the performance table, and it is simplified as follows:
employee | Employees table |
name | Names of employees, suppose there is no repeated name. |
gender | Genders of employees. |
We have already computed out the name list of “good” salespersons, and the relatively natural idea is to seek out their genders from the employee table using name list, and count the number. But in SQL, it is necessary to use join operation to get information across tables . In this way, following the initial result, SQL will be written as:
select employee.gender,count(*)
from employee,
( ( select top 10 sales from sales_amount where product='AC' order by amount desc )
intersect
( select top 10 sales from sales_amount where product='TV' order by amount desc ) ) A
where A.sales=employee.name
group by employee.gender
With only an associated table more, it is made so over-elaborate and in reality there are rather more cross-table storages and they are often multi-layered. For example, for salespersons, there are departments where there are managers, and now we want to know by which managers these “good” salespersons are managed. Then there are three table joins, and it is indeed no easy job to write clear where and group in this computation.
This is just the fourth important disadvantage of SQL as we want to say: Lack of object reference, in relational algebra, the relations between objects completely depends on foreign key. This not only makes the efficiency very low in looking for relation, but also makes it impossible to directly treat the record pointed by foreign key as the attribute of primary record . Try thinking, can the above statement be written as this:
select sales.gender,count(*)
from (…) // …is the SQL computing the “good” salespersons above
group by sales.gender
Evidently, this statement is not only clearer, and at the same time, the computation will also be more efficient (without join computation).
We have analyzed, through a simple example, the four important difficulties of SQL. We believe this is just the main reason why SQL fails to reach the original intention of its invention. The process of solving business problem based on a kind of computation system is in fact the process of translating business problems into formalized computation syntax (similar to the case in which a pupil solves application problem, translates the problem into formalized four arithmetic operations). Before overcoming these difficulties, SQL model system rather does not comply with people’s natural thinking habit, causing great barriers in translating problems, making it very difficult for SQL to be applied, on a large scale, in data computation for business problems.
For still another example which is easily understood by programmer, use SQL as data computation, which is similar to the case in which assembly language is used to complete four arithmetic operations. We very easily write out the calculation expression such as 3+5*7, but to use assembly language (take X86 as the example), it needs to be written as
mov ax,3
mov bx,5
mul bx,7
add ax,bx
In either writing or reading, such code is far inferior to 3+5*7 (it will be more troublesome if we come across decimal). Though it cannot be regarded as a big problem to a skilled programmer, to most people, however, this kind of writing is too hard to understand. In this sense, FORTRAN is really a great invention.