An example to illustrate hadoop code reuse
Posted by raqsoft in Java Development and Database Computation on Jan 9, 2014 3:00:00 AMThe MapReduce of Hadoop is a widely-used parallel computing framework. However, its code reuse mechanism is inconvenient, and it is quite cumbersome to pass parameters. Far different from our usual experience of calling the library function easily, I found both the coder and the caller must bear a sizable amount of precautions in mind when writing even a short pieces of program for calling by others.
However, we finally find that esProc could easily realize code reuse in hadoop. Still a simple and understandable example of grouping and summarizing, let’s check out a solution with not so great reusability. Suppose we need to group the big data of order (sales.txt) on HDFS by salesman (empID), and seek the corresponding sales amount of each Salesman. esProc codes are:
Code for summary machine:
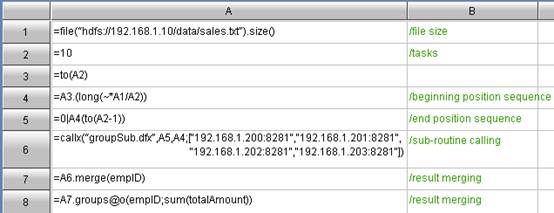
Code for node machine:

esProc classifies the distributed computing into two categories: The respective codes for summary machine and node machine. The summary machine is responsible for task scheduling, distributing the task to every task in the form of parameter, and finally integrating and summarizing the computing results from node machines. The node machines are used to get a segment of the whole data piece as specified by parameters, and then group and summarize the data of this segment.
As can be seen, esProc code is intuitive and straightforward, just like the natural and common thinking patterns. The summary machine distributes a task into several segments; distributes them to the unit machine to summarize initially; and then further summarizes the summary machine for the second time. Another thing to note is the esProc grouping and summarizing function “groups”, which is used to perform the grouping action over the two-dimensional table A1 by empID and sum up the values of amount fields. The result will be renamed to the understandable totalAmount. This whole procedure of grouping and summarizing is quite concise and intuitive: A1.groups(empID;sum(amount): totalAmount)
In addition, the groups function can be applied to not only the small 2D table, but also the 2D table that is too great to be held in the memory. For example, the cursor mode is adopted for the above codes.
But there are some obvious defects in the above example: The reusability of code is not great. In the steps followed, we will rewrite the above example to a universal algorithm independent of any concrete business. It will be rewritten to control the code flow with parameters, so as to summarize whatsoever data file. In which, the task granularity can be scheduled into arbitrary number of segments, and the computing nodes can be specified at will. Then, the revised codes are shown below:
Code for summary machine. There are altogether 4 parameters defined here: fileName: Big data file to analyze; taskNumber: Number of tasks to distribute; groupField: Fields to group; sumField: Fields to summarize. In addition, the node machine is obtained via reading the profiles.
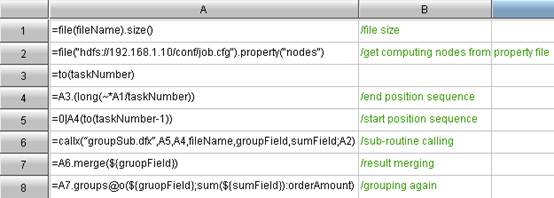
Code for node machine. In the revised codes, 4 variables are used to receive the parameter from summary machine. Besides the file starting and ending positions (start and end) from the first example, there are two newly-added fields. They are groupField: Fields to group; and sumField: Fields to summarize.

In esProc, it is much easier to pass and use parameter because users can implement the common grouping and summarizing with the least modification workload, and reuse the codes easily.
In Hadoop, the complicated business algorithm is mainly implemented by writing the MapReduce class. By comparison, it is much more inflexible to pass and use parameters in MapReduce. Though it is possible to implement a flexible algorithm independent of the concrete business, it is really cumbersome. Judging the Hadoop codes, the coupling degree of code and business is great. To pass the parameters, a global-variable-like mechanism is required, which is not only inconvenient but also hard to understand. That’s why so many questions about MapReduce parameter-passing are here and there on many Web pages. Lots of people feel confused about developing universal algorithms with MapReduce.
In addition, the default separator in the above codes is the comma. It is obvious that users only need to add a variable in a similar way to customize it to any more commonly-used symbol. With it, they can also implement the common action of data filtering and then grouping and summarizing easily. Please note the usage of parameter groupField. It is used as the character parameter in the cell A6, but the macro in A8. In other words, ${gruopField} can be resolved as the formula itself, instead of any parameter in the formula alone. This is the work of dynamic language. Therefore, esProc can realize the completely flexible code, for example, using the parameter to control the summary algorithm to perform sum up or just count, seek the average value or maximum.
“Macro” is a simple special case of dynamic language. esProc supports a more flexible and complete dynamic language system.
As you may find from the above example, esProc can implement Hadoop code reuse easily, and basically achieve the goal of “Write once, run anywhere!”. Needless to say, the development efficiency can be boosted dramatically.
Comments