
Join multiple tables with “join”
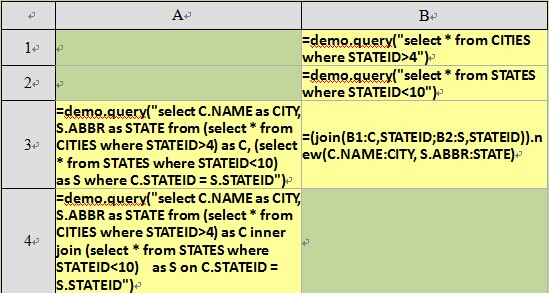

The SQL statements used in A3 and A4 are inner join, but they have different syntax. When the data of two tables are being joined, only the data that has inter-table relations with each other will be fetched. The returned result in A3, A4 and B3 are all the same. Note that the order of records in the results returned by SQL and esProc respectively may be not the same:
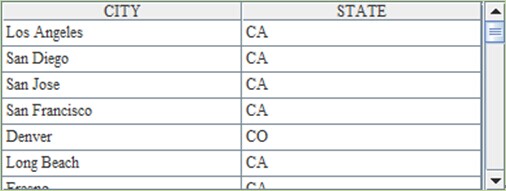
The SQL statement in A5 is a left join. When the data of the two tables are being joined, besides the data that has inter-table relations with each other, all the unrelated data in the first table will also be fetched. This means, in the result, field STATE may be null and field CITY won’t be null. This case, in fact, is the foreign key relationship. To join tables together in esProc, both switch and join@1() function, in which the option 1 is a digit, can be used. Letter l won’t appear in esProc options for fear of confusion. The returned result in A5 and B5 are the same. As the above, the order of records in the results returned by SQL and esProc respectively may be not the same:

The SQL statement in A6 is a full join. When the data of the two tables are being joined, all data of both tables after relating will be fetched, meaning both of the two fields: STATE and CITY, in the result may be null. The operation can be performed with join@f() function in esProc. The returned results in A6 and B6 are the same but the order of records in them may be different:
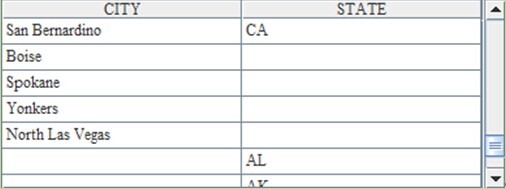
The SQL statement in A7 is right join. When the data of the two tables are being joined, all the unrelated data in the second table, besides the data that has inter-table relations with each other, will be fetched. This means, in the result, the field CITY may be null but field STATE won’t be null. Without a similar usage, esProc needs to switch the positions of the parameters in join@1(), the left join function, to complete the same operation. The returned results in A7 and B7 are the same though the order of records in them may be different:
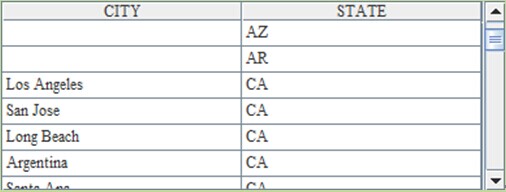
Union the results with “union”
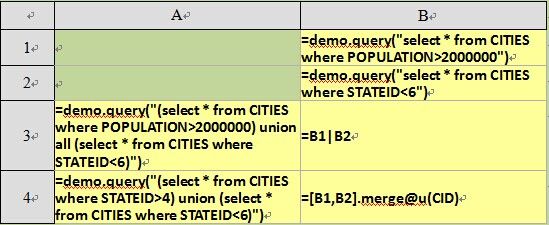
Union all or union can be used in the SQL statements to union the data from two result sets. But in esProc, two sequences can be concatenated to merge the data from two result sets completely. The results in A3 and B3 are the same:
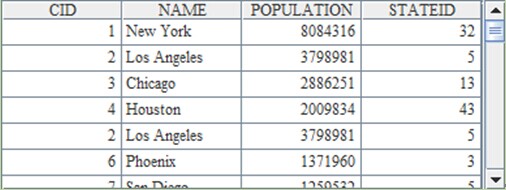
merge@u() function can be used in esProc to remove the duplicates in the result. The results in A4 and B4 are the same:
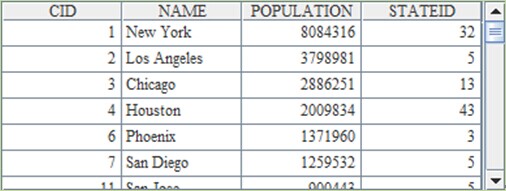
Only the first of the two duplicate records of Los Angelesin the previous resultis kept.