We often need to process text file data while programming. Here is an example for illustrating how to group and summarize text file data in Java: load employee information from text file employee.txt, group according to DEPT and seek COUNT, the number of employee, and total amount of SALARY of each group.
Text file employee.txt is in a format as follows:
Java’s way of writing code for this task is:
- 1. Import data from the file by rows and save them in emp, the multiple Map objects of sourceList, the List object.
- 2. Traverse the object of sourceList, perform grouping according to DEPT and save the result in list, which contains different List objects of group, the Map object.
- 3. Traverse group and then traverse each DEPT’s list object, and sum up SALARY.
- 4. While traversing group, save the values of DEPT, COUNT and SALARY in result, the Map object, and the results of different departments in resultList, the List object.
- 5. Print out the data of resultList.
The code is as follows:
public static void myGroup() throws Exception{
File file = new File("D:\\esProc\\employee.txt");
FileInputStream fis = null;
fis = new FileInputStream(file);
InputStreamReader input = new InputStreamReader(fis);
BufferedReader br = new BufferedReader(input);
String line = null;
String info[] = null;
List<Map<String,String>> sourceList= new ArrayList<Map<String,String>>();
List<Map<String,Object>> resultList= new ArrayList<Map<String,Object>>();
if ((line = br.readLine())== null) return;//skip the first row
while((line = br.readLine())!= null){
info = line.split("\t");
Map<String,String> emp=new HashMap<String,String>();
emp.put("EID",info[0]);
emp.put("NAME",info[1]);
emp.put("SURNAME",info[2]);
emp.put("GENDER",info[3]);
emp.put("STATE",info[4]);
emp.put("BIRTHDAY",info[5]);
emp.put("HIREDATE",info[6]);
emp.put("DEPT",info[7]);
emp.put("SALARY",info[8]);
sourceList.add(emp);
}
Map<String,List<Map<String,String>>> group = new HashMap<String,List<Map<String,String>>>();
//grouping object
for (int i = 0, len = sourceList.size(); i < len; i++) {//group datafrom different DEPT
Map<String,String> emp =(Map) sourceList.get(i);
if(group.containsKey(emp.get("DEPT"))) {
group.get(emp.get("DEPT")).add(emp) ;
} else {
List<Map<String,String>> list = new ArrayList<Map<String,String>>() ;
list.add(emp) ;
group.put(emp.get("DEPT"),list) ;
}
}
Set<String> key = group.keySet();
for (Iterator it = key.iterator(); it.hasNext();) {//summarize the grouped data
String dept = (String) it.next();
List<Map<String,String>> list = group.get(dept);
double salary =0;
for (int i = 0, len = list.size(); i < len; i++) {
salary += Float.parseFloat(list.get(i).get("SALARY"));
}
Map<String,Object> result=new HashMap<String,Object>();
result.put("DEPT",dept);
result.put("SALARY",salary);
result.put("COUNT",list.size());
resultList.add(result);
}
for (int i = 0, len = resultList.size(); i < len; i++) {//print out the resulting data
System.out.println("dept="+resultList.get(i).get("DEPT")+
"||salary="+resultList.get(i).get("SALARY")+
"||count="+resultList.get(i).get("COUNT"));
}
}
The results after the code is executed are as follows:
dept=Sales||salary=1362500.0||count=187
dept=Finance||salary=177500.0||count=24
dept=Administration||salary=40000.0||count=4
dept=Production||salary=663000.0||count=91
dept=Marketing||salary=733500.0||count=99
Here myGroup function has only one grouping field. If it has multiple grouping fields, nested multi-layer collections class is needed and the code will become more complicated. As myGroup function has fixed grouping fields and summarizing fields, if there is any change about the fields, we have no choice but to modify the program. This robs the function of the ability to deal with situations of flexible and dynamic grouping and summarizing. In order to enable it to handle these situations as well as SQL statement does, we need to develop additional program for analyzing and evaluating dynamic expressions, which is a rather difficult job.
As a programming language specially designed for processing structured (semi-structured) data and able to perform dynamic grouping and summarizing easily, esProc can rise to the occasion at this time as a better assistive tool. It can integrate with Java seamlessly, enabling Java to access and process text file data as dynamically as SQL does.
For example, group according to DEPT and seek COUNT, the number of employees, and the total amount of SALARY of each group. To do this, esProc can import from external an input parameter “groupBy” as the condition of dynamic grouping and summarizing. See the following chart:
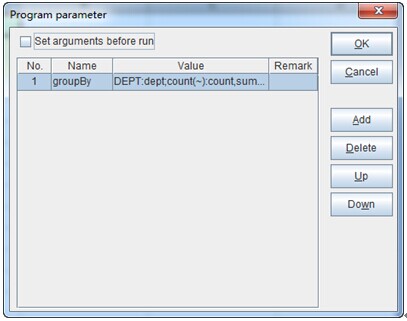
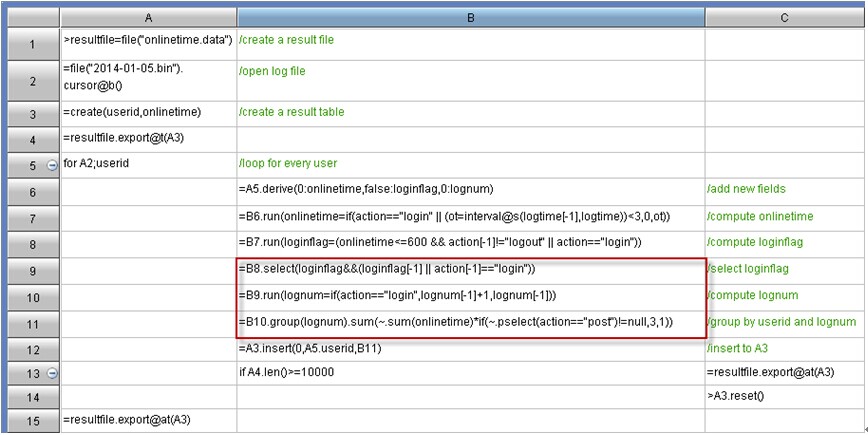
The value of “groupBy” is DEPT:dept;count(~):count,sum(SALARY):salary. esProc needs only three lines of code as follows to do this job:
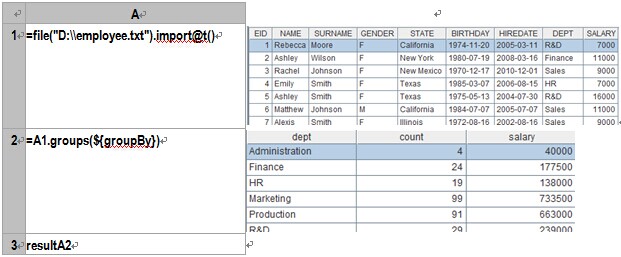
A1:Define a file object and import the data to it. The first row is the headline which uses tab as the default field separator. esProc’s IDE can display the imported data visually, like the right part of the above chart.
A2:Group and summarize according to the specified field. Here macro is used to dynamically analyze the expression in which groupBy is an input parameter. esProc will first compute the expression enclosed by ${…}, then replace ${…} with the computed result acting as the macro string value and interpret and execute the result. In this example, the code we finally execute is =A1.groups(DEPT:dept;count(~):count,sum(SALARY):salary).
A3:Return the eligible result set to the external program.
When the grouping field is changed, it is no need to change the program. We just need to change the parameter groupBy. For example, group according to the two fields DEPT and GENDER and seek COUNT, the number of employees, and the total amount of SALARY of each group. The value of parameter groupBy can be expressed like this: DEPT:dept,GENDER:gender;count(~):count,sum(SALARY):salary. After execution, the result set in A2 is as follows:
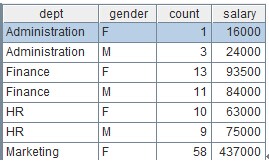
Finally, call this piece of esProc code in Java to get the grouping and summarizing result byusing JDBCprovided by esProc. The code called by Java for saving the above esProc code as test.dfx file is as follows:
// create esProc jdbc connection
Class.forName("com.esproc.jdbc.InternalDriver");
con= DriverManager.getConnection("jdbc:esproc:local://");
//call esProc code (the stored procedure) in which test is the file name of dfx
- com.esproc.jdbc.InternalCStatement st;
st =(com.esproc.jdbc.InternalCStatement)con.prepareCall("call test(?)");
// set parameters
st.setObject(1,"DEPT:dept,GENDER:gender;count(~):count,sum(SALARY):salary");//the parameters are the dynamic grouping and summarizing fields
// execute the esProc stored procedure
st.execute();
// get the result set
ResultSet set = st.getResultSet();
Here the relatively simple esProc code can be called directly by Java, so it is unnecessary to write esProc script file (like the above test.dfx). The code is as follows:
st=(com. esproc.jdbc.InternalCStatement)con.createStatement();
ResultSet set=st.executeQuery("=file(\"D:\\\\esProc\\\\employee.txt\").import@t().groups(DEPT:dept,GENDER:gender;count(~):count,sum(SALARY):salary)");
The above Java code directly calls a line of code from esProc script: get data from the text file, group and summarize them according to the specified fields and return the result toset, Java’s ResultSet object.