In one of my previous entries I may have inadvertently given the impression that in order to do microservices you need Linux containers, such as Docker. I want to clarify that so have written a new article which hopefully clarifies where those containers matter, especially in the Java world where we already have a container in the form of the JVM.
After writing my previous entry of how a container image, such as Docker, makes a natural unit of failure for an individual microservice or groups of related services, I wanted to follow up on one of the things I didn't get into detail on: state. Where does the state of the microservice reside? Is it within the container image, which may seem intuitively correct, or is it outside of the image? I've been thinking about state and replication for many years (well over 20) and was revisiting one of my earlier papers recently and got to thinking that it was relevant to microservices, or at least containers (since of course a container doesn't need to be tied to only being useful for microservices!) With that in mind, I found a few hours today to write up some thoughts on state and containers in general, but specifically microservices, Hopefully it makes some sense.
Another mini-vacation so another few hours to sit and write down some things that have been rumbling around in my head for a while. This time it's about Docker (container) images, microservices and how they can be combined to provide a natural unit of failure when building multi-service applications or composite services. Check it out on my personal blog, but hopefully the conclusion should be obvious:
"If you are building multiple microservices, or using them from other groups and organisations, within your applications or composite service(s), then do some thinking about how they are related and if they should fail as a unit then pull them together into a single image."
It's a Saturday evening and I've finally had time to put down further thoughts on container-less development. OK, ignore the fact that I'm at home on a Saturday night instead of out "on the town" - but work is still my hobby (or is it vice versa?) and I'm enjoying it!
I've finally made time to write down some of my thoughts on microservices and how they should relate to SOA and other approaches which have gone before. I've cross-linked the article here for those who may be interested. As I mentioned in the InfoQ interview, I think some of the recent advances in development tools, such as docker-based containers, should make service development easier. However, if we'd had them 10 years ago they'd have fallen under the banner of SOA and I don't think we'd have coined a new term to describe a specific implementation. Whether it's SOA, microservices or some other term, I do think that in the last year or so there have been some interesting developments around frameworks, languages, containers etc. that do make a difference for distributed service-based applications. We just need to join them together with all of the good things we did over the past decade or so and called SOA.
I've been thinking about approaches to container-less development and deployment for a while. However, it was whilst I was at DevConf.cz the other day that I decided to write down some of my thoughts. Well that and the interview I did with Markus for my keynote at JavaLand in a few weeks. I wanted to write something that was objective though and without pushing a particular implementation agenda - often hard given what I do as my day job. However, that's the reason I wrote it over on my personal blog and am cross-linking it here. Obviously I do think that the work we've been doing with AS7/WildFly/EAP is one of the main catalysts for improving the whole dev-to-deploy experience when people work with a Java EE container, with projects such as Forge and Arquillian as critical pieces in that puzzle. There's more to be done and I'm excited about some of the improvements the teams have planned. And I also think that new approaches such as Vert.x offer a view of where things are going and can still benefit from experiences and components elsewhere.
As the saying goes ... a long time ago in a galaxy far, far away ... Red Hat was created around Linux and did a great job of working with communities and customers to provide the best enterprise-grade Linux platform around and to this day. However, over the years Red Hat's aspirations and reach have grown to include virtualisation, storage, cloud, middleware and mobile, to name but five new pieces. Whilst the operating system is critical for running applications or services and Linux has all the hooks you'd need to build a huge range of them, they're mostly too low level for many developers. Hence the need for these advanced capabilities so you don't have to do that - someone else has done that hard work for you. Additionally, at least where enterprise software is concerned, those companies and groups will have ironed out many of the bugs and security flaws. Following on from this logic, whilst we've implemented a number of critical technologies "in house", Red Hat has also acquired them - why build when we can buy? JBoss, FeedHenry, eNovance, Makara, Inktank ... We've done a pretty good job of bringing in key software components and adding them to our evolving stack.
I can't think of another pure open source company that has such a deep and broad stack as Red Hat. And this is important for the evolving world we live in today. Whether it's running critical back-end services on RHEL, Java and Java EE with EAP, integration via Fuse, both on or off OpenShift, or even addressing Internet of Things with something like MQTT (A-MQ) and Vert.x, we've got so many of the software tools that a huge range of developers need these days. And these aren't disparate capabilities that don't know about each other - we're continually working hard to make everything we do work well together. In essence, the Red Hat Platform is all of our deep, broad stack integrated and operating together. Of course pieces of this Platform can be used independently of each other, but that's just another compelling reason for developers to consider using it - you're not locked into having to use all or nothing.
A few weeks ago I have the privilege of giving the keynote at OpenSlava 2014. Rather than talk about JBoss or Red Hat technologies/projects I decided to try something new and talk about how open source has impacted our lives over the past few decades. Most of us take this stuff for granted and I know that's definitely the case for me: having lived through all of it and helped participate in some of it, I found pulling together the presentation both enjoyable and a reminder. I hope to get the opportunity to give the presentation again as I've already thought of a few other things I'd like to add to it and also get more audience participation. Hopefully those people at OpenSlava got as much out of it as I did writing it.
The video of the presentation is available online and linked earlier. The actual presentation is also available. However, for those who can't watch the video I thought I'd include a few of the slides. We all know about Linux and the huge impact it has had on the software industry since it started over twenty years ago:

Not only was it also used within the PS3 but it's the basis of Android, a fact many of those phone users don't know. Then of course we have to remember the role open source played in creating the Web:

And for those in the audience who didn't know, the gopher is from Caddyshack! Of course we talk about the Web and implicitly believe we all understand what "it" means and has become. I thought this image of the connectivity map for the Web helped bring it and hence the impact open source has had on our lives, to life:

Of course Java, not open source originally, has had its own significant impact on the software industry. I like to think that JBoss/Red Hat have played an important role in that journey too. But as this slide shows, it's also had an impact outside of our industry including an important one for many kids: Minecraft. I've seen children teach themselves all about Java, jars, manifest files etc. just so they can create mods for Minecraft and exchange them with their friends! I'm not sure any other language could have had quite that impact without open source!

I've already touched on how open source is helping to drive mobile, and in the presentation I also mentioned cloud. Of course there's also Big Data and NoSQL, which are most definitely being driven by open source first and foremost. So over the years where open source was the follower, now it is the leader.

As I concluded in the presentation, open source is no longer a second-class citizen, the domain of some developers working "on the edge". It's often the first line of attack to a problem and has become accepted by many users and developers. Where we take it now is no longer constrained by hurdles such as persuading people open source is a viable alternative (often there is no alternative). Now the limitations are our imagination and determination to make open source solutions work!

I'll leave it as an exercise to the interested reader, but I've written many times about the capabilities that we have in the JBoss middleware products and projects. Many of them have been developed over several years, some such as Narayana/JBoss Transactions, since before Java was even called Java! Our customers and communities regularly deploy the software we have developed in conjunction with our communities, into mission critical environments.

Obviously given our heritage we've focused on what this all means for Java and Java EE. But our various polyglot efforts, around JRuby, Clojure, Ceylon and other languages have shown clearly that the capabilities can be made available to a wider variety of languages than just Java. But obviously not all languages people are interested in run on the JVM and even those that do, such as JavaScript, have a massive non-JVM following. I've said time and again that our industry can't afford to re-invent wheels, especially critical wheels such as transactions, security and high performance messaging. In most cases it's a waste of time or brings dubious value. Making these capabilities available to other languages even outside of the JVM has to be a serious consideration before any wheel reinvention takes place! But how do we do this?
In the "good old days" before J2EE we had CORBA where everything was a service. With J2EE and threads within the Java language, people took co-location of capabilities as the default - remote invocations do add some overhead after all (give them a try!) Recently we've had SOA, where business components can be services. Along comes cloud and Software-as-a-Service takes off - the clues in the name! Services offer one such possibility and with the increasing adoption of REST (typically over HTTP) this is an approach with which many users and developers are comfortable. Exposing business components as services is just one step. Taking core capabilities and exposing them as services (just as CORBA did) is the obvious next step and something others have done, especially in the cloud arena. About 5 years ago I gave a presentation about this, a slide from which is included, with circles representing core Java EE capabilities and rectangles as containers, JVMs or VMs:
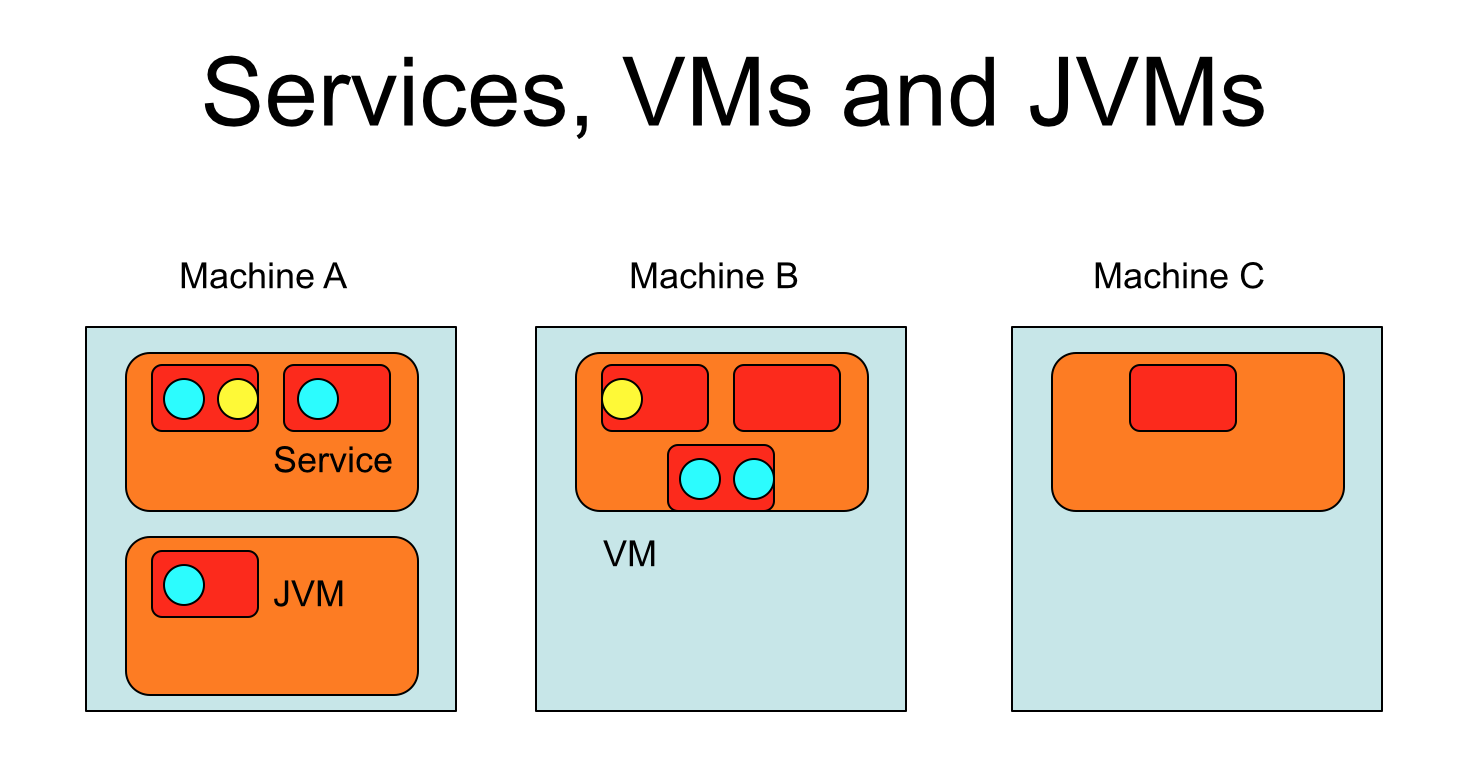
Now where's all of this going? Well we (Red Hat) have made some progress towards approach this over the years but recently we've seen a significant acceleration. With the advent of xPaaS, integrated services and products for the DevOps world, and now Fabric8, Kubernetes and OpenShift, the creation of docker-based services (components) is happening now. Our aim is to ensure that these services are available to all (public, private, hybrid cloud as well as non-cloud deployments). Within the cloud they'll appear via Fabric8/OpenShift within xPaaS, perhaps as individual services or applications, or within a composite - time will tell, as we are quite early in some aspects of this development process.
Ultimately what docker, Kubernetes, Farbric8, OpenShift and many other efforts allows us to do is realise a long held belief and define an enterprise middleware layer that is independent of programming language - the Red Hat JBoss Enterprise Middleware layer. Often our industry spends too much time focussing on the specific languages, the latest shiny object and not enough on the what it takes to build enterprise mission critical applications. This is all part of improving developer productivity, because without these capabilities (transactions, messaging etc.) someone has to implement them and if that's your developers then they're clearly not able to spend time working on the applications or business components you're paying them to build! With our approach we're exposing these services to whatever language makes sense for our customers and communities; those we don't get around to can be worked on by our communities, as that's the beauty of open source!
We are embracing and extending our Java heritage but in whatever language makes sense. We have the heritage and pedigree and we should build upon this. The JBoss name should become synonymous with this enterprise layer with associated capabilities (services) irrespective of the programming language you're using. We started this with JBossEverywhere but it needs to go much further. In the polyglot, mobile and cloud era the language for backend services can be varied and often down to an individual developer, but the maturity and enterprise worthiness that the backend provides should not be open to debate. If you are relying upon your backend to be available, reliable, fault tolerant etc. then the maturity, pedigree and heritage you're using are extremely important.
JBoss is a platform for the future.
I've done a few acquisitions over the years along with this kind of blog post welcoming the new team to the fold. It's with great pleasure that I can do it again and this time for FeedHenry. The official press release can be located here, but I want to be more personal than that. We've been working in the area of mobile and backend-as-a-service for a while now, with the AeroGear and LiveOak projects. FeedHenry compliments them (and vice versa) as well as offering the opportunity to make the collective an even more compelling developer and deployer experience for our customers and communities - especially when you factor in OpenShift and xPaaS! The technology that we've acquired is wonderful, but let's not forget their (our) team: from what I've seen over the past few months they are as passionate about their work as we are within JBoss and Red Hat, so that should be a good meeting of minds. The challenges of working remotely are something we have met and bettered here for many years, so I'm not worried that the FeedHenry team is located in one place and the rest of the teams are dotted around the globe.
Now of course the fact that FeedHenry uses Node.js (and Java) within their offerings gives us another opportunity: exploring the Node.js developer landscape in more depth and seeing how we can bring some of our enterprise capabilities to the fore. I expect projects such as Vert.x and Nodyn to play a critical role here. All of the teams involved in the integration and forward development of the JBoss/FeedHenry combination will have ample opportunities to learn from each other and benefit from individual and shared experiences. So don't worry that the acquisition of a company that uses Node.js means we're ditching Java because nothing could be further from the truth. We are a polyglot company and this acquisition bolsters that story!
Onward!
It may seem strange to think of enterprises and IoT, but there are already many companies looking to use the data they obtain from "edge" devices, such as sensors, in their day-to-day business. Of course as a result we've all heard of Big Data and how it plays here with the need to store Petabytes of information so that analytics can be performed on it, both in realtime and batched. But this is just the start of where enterprise and IoT will intersect. When I talk about Enterprise IoT I'm implicitly thinking about the kinds of scenarios I've discussed before around JBoss Everywhere. Now of course we should abstract away the specific technology because you could do this in a variety of ways. However, the use cases remain.
Today people consider edge devices as dumb; message exchanges are best effort; they're typically stateless; they do one thing well, such as read the ambient temperature; they only know about one endpoint with which they exchange data; they can't be easily (field) updated; network bandwidth is limited. All of these restrictions are imposed by the limited scenarios we have today, or the limits of the technology. However, if the last 50 years of software and hardware evolution have told us anything, it's that both of these problems will change and probably more rapidly than many people believe.
I believe we are in the very early years of IoT and as technology waves of the past have shown us, these are typically the periods where advancements come quick and furious. Why should edge devices be limited by memory or processor? A Raspberry Pi today costs $30 but in less than 18 months something equivalent will be sub $10 and the form factor will look more like an RFID chip. Developers will want to store more data on these devices so they can do local processing (prediction), maintaining state to help them determine what to do next. They will become much more autonomous, with some of them having peer-to-peer relationships with other devices, clients and servers within the IoT cloud. These devices will communicate with each other. They may work together for fault tolerance and reliability, sharing data, requiring consistent updates to that data. And they'll need to be much more secure so they cannot be hacked or spoofed. Certain message exchanges may need to be delivered reliably as well as capturing an audit trail for non-repudiation purposes.
The potential for Enterprise IoT is significant and only limited by our imaginations. In just the same was as two decades ago edge devices of the time evolved into today's enterprise critical laptops and servers! And of course I want to see JBoss and Red Hat technologies and communities leading the way.
Over a decade ago JBoss Inc was formed and back then the company was synonymous with J2EE and the JBoss Application Server. By 2006 and the Red Hat acquisition of JBoss we'd grown the projects to include Drools, jBPM, JBossESB, JBoss Portal and many others, but the predominate association of the term JBoss remained with Java Enterprise Edition and the application server. Over the last 8 years, however, Red Hat has grown the JBoss pantheon of projects and products significantly, so now it includes MRG-M, Data Virtualisation (through the acquisition of MetaMatrix), Fuse including A-MQ (through the acquisition of FuseSource and the associated projects), BPM (through the acquisition of Polymita and the work of our homegrown Drools and jBPM teams), BRMS (great vision and work by the expanded Drools team), mobile (with AeroGear, HTML5 and Objective-C), and other non-Java language support including JRuby, Clojure and Ceylon (putting Red Hat amongst the likes of Google and Apple pushing the frontiers of language development). Today in 2014, more than a decade since the term JBoss was first coined, it means so much more than Java let alone Java Enterprise Edition. Who knows what more it will mean in another decade?! Onward!
It doesn't seem like nearly 6 months ago when I mentioned that instead of a JUDCon preceding Summit as we've done in the past we'd have DevNation. Since then we've been looking at when and how to organise the new JUDCon and it was getting tricky to fit it in amongst the various conferences and workshops that also dot our collective landscape. One thing that we've always prided ourselves on is that JUDCon is "By Developers For Developers" and it has its roots in various larger project face-to-face meetings where we'd invite the communities to attend, give input and maybe listen to presentations. We still have those larger project meetings but we tend not to run them in the same way - not because we don't want to, but simply because JUDCon came along and made it easier to focus these kinds of things. So if we can't have a larger JUDCon at this time of year, why not go back to the original format? This is precisely what we've done this time around with JUDCon Boston 2014. It's a one day event being hosted just after the team meeting and with a focus this time on mobile, micro-presentations and a group hacking event not to be missed! If this is a success then I'd like to see us duplicate this if possible at many more such meetings around the world. If you're in or near Boston and want to come along, see the registration page!
Onward!
In the words of Rod Serling and the Twilight Zone: "Submitted for your approval". Consider a world where you're a developer and you've spec-ed out a large project you need to develop, either alone or with a group, and you know you need integration, a web server and definitely some enterprise capabilities such as reliability, transactions, security etc. And you'll be using good SOA practices throughout, of course! You sit down at your laptop, which doesn't have anything installed on it yet, and start to leaf through an online repository of software (app-store/service-store) that will help you achieve your goals. There's a core development environment (implemented on the JVM of course, though perhaps you want to use a combination of languages so maybe Java isn't your first choice) and for the sake or argument let's assume you're developing locally initially, so no Web-based IDE. Your initially selected packages download and off you go in a matter of minutes, with your friendly neighbourhood source code repository either created as part of this process or one you've got to hand already.
Now whilst it's nice to work alone at times, this project really requires more than one person and it's unlikely to ever be deployed on your laptop. So … to the cloud! All of the software components you need are either already deployed or deployed automatically as you migrate your requirements. As with the local (original) configuration, they're also integrated seamlessly with each other and with your IDE, so the only differences you might notice will be due to the interconnect between yourself and the cloud (though if you have redundant connectivity options then even this may be temporary and perhaps not even noticed by you). There are also core services deployed into the cloud, such as messaging (Messaging-as-a-Service), data (Database-as-a-Service), and others that you can use directly where necessary. As the team of developers continue to work, using their shared code repository and infrastructure, you may start to think about various non-functional aspects of the finished application which are critical when it comes to be deployed. These would include QoS requirements, such as average uptime, peak load requirements etc. All you have to do is define the QoS, clear in your understanding that the Cloud on which the application will be deployed knows how to distribute your application, non-functional components/services that you may not even be using yet but which are required to match your QoS, state etc. to any needed machines automatically and opaquely, i.e., without human intervention.
As the application development goes on you need more capabilities, such as cacheing or access to a large-scale in-memory data grid; you may even need to move up the stack and pull in requirements from different categories of users. For instance, your development team may create a range of services which can be used directly by users or composed together into other services to provide a composite capability/service. To do this it may be easier to think in terms of workflows or task flows; in fact the infrastructure on which you are developing may even pop up and suggest this to you (hopefully not as annoying as Clippy!) Further up the application stack the user may move from a developer who thinks in terms of code, interfaces, exceptions, messaging etc. and works with concepts such as choreography, orchestration, swim lanes. This is precisely where Business Process Management tools come into play and fortunately your Cloud has that service to offer on demand when you or others in the team need it; just select it and it is deployed into your development environment and automatically searches for the services you've created, making them available for further use.
Nearing completion of the application, you decide that whilst you want this application to run on the Cloud most of the time, you don't want to rely on a public Cloud entirely. Maybe you have some data that cannot be pushed to the public Cloud due to the sheer size of the data or for regulatory reasons (fortunately your development environment also has data virtualization techniques available which will allow you to partition the data for your application and also associate metadata with it such that the underlying Cloud knows where it can and cannot migrate the data to meet other QoS requirements). Maybe for peak periods you want to cloud burst to a private data centre (or vice versa). Whatever the reasons, you need to ensure that there's a similar infrastructure deployed on to these private machines (let's call it a private cloud for now) and tied into the public cloud. Again, a few clicks of the application repository (or administration menu) and everything is selected and downloads begin in the background, or even on demand, i.e., only encumber these machines when there's a need).
That's it. You step back and take a look at what the team have developed and how. In fact you can view all of this at various levels of granularity, from individual lines of code, to entire service interfaces and contracts, using the same toolchain you've been using. All of the interconnects between services that your team have created are shown up, and once it's running you'll be able to drill down onto specific machines, services and users to determine hotspots. gauge how well the application is running etc. All of this has been done by your team with no help from external service providers, IT teams or others not core to developing the application. Anything that has needed to be deployed, either to assist in the development or in the deployment has been triggered by your team and fulfilled by the Cloud infrastructure itself. Running the application requires very little (hopefully no) administration by you or the team, since the infrastructure is self-monitorig and adapts to changes in requirements, fault hotspots, patches itself when needed (maybe ignoring some patches that don't fix issues relevant to the application), …
Perhaps over the weeks and months that follow, your team or the client for whom you're working, buy more hardware (laptops, desktops, even IoT devices) that can be provisioned for us by the Cloud and this application: all you do is register them with the Cloud you're using and it downloads some basic infrastructure (fabric), perhaps add metadata to tell the Cloud when (time of day) these devices can be used or under what conditions (e.g., load is below 20%). Again, no programming/development is required: you "just" click-and-go! The development infrastructure may even be able to predict what you need before you do and install components so they are there when needed. Not so unreasonable given techniques such as Bayesian Inference Networks, or the fact that an algorithm is now a company board member!
Hopefully this doesn't sound too far fetched. And hopefully it sounds like something which makes sense to you, because this is the kind of thing we're trying to accomplish with xPaaS. Some of this isn't too far from what we demonstrated earlier this year. And whilst there's still some way to go before we have all of this, we're making great progress with efforts like Fabric8. However, a lot of the work we need to do is presentation related: how we make available these technologies so it really is a lot more point and click and a lot less writing of much code. Don't get me wrong: I've never been a believer in "zero coding" development tools aimed at programmers, but for certain categories of developer it's possible to get close (but no closer).
Adding in capabilities to your development (and deployment) environment as you need them is something we've become used to over the years with the likes of maven, but what I've mentioned above goes much further. It needs to be as natural and opaque as selecting an app on a tablet or mobile phone; any dependencies (such as other apps) are downloaded automatically. As you download capabilities (augment your environment) so too will they be downloaded to your co-workers on the same project - perhaps there'd be the notion of groups for developers so only if you're in a specific group(s) do you receive this auto-update when your colleagues in the same group realise they need some new capability. And like I said several years ago, how this happens under the covers is not necessarily something that is exposed to the users (the opaque references I keep making), but could be based upon dynamically updating containers with capabilities as and when they're required.
Finally another key component to this Utopian Future is the typical cloud billing mechanism: pay for what you need when you need it. The developers don't have to buy development licences or support ad infinitum but only for the duration of the development process (though some are obviously needed for support and maintenance later). The customer needs buy deployment/runtime licences or support for the duration of the application's lifetime, which could be measured in months or years, but which typically still only get billed per minute of execution. So if the application gets shut down for specific periods of the week or year, there's no need to pay for them.
Maybe this all seems far fetched. Maybe it's obvious to you. After all we and others have been talking about things like this for a while. We're continuing to head in these directions with xPaaS, Fabric8, WildFly, OpenShift and a large range of other efforts. Working with upstream communities, partners and customers this is an exciting time!