This content has been marked as final.
Show 18 replies
-
1. Re: Scoping, what's a metric or not?
theute Sep 8, 2014 5:53 AM (in response to genman) 1 of 1 people found this helpful
1 of 1 people found this helpfulFirst, thank you Elias one more time for sharing your very valuable experience !
I am also wrapping my head around this question.
At the moment we are talking about 4 separate sub-projects (with soft dependencies between them), with codenames more than real names:
- RHQ Metrics - this one which is about storing metrics with the definition of "some value that change over time for which we store the value at regular time"
- RHQ Events - Events are discret events happening at "some" time (Deploying a new version of a software, A machine shutting down or booted... Now I also wonder how scalable this needs to be, a "user who opens a session" could be considered an event, while we would rather want to store the number of opened sessions over time with RHQ Metrics)
- RHQ Availability - Some framework to specify rules to tell if a resource is available (and that info needs to persist)
- RHQ Alerts - For alert definitions and alert store as well
Those sub-projects would be wrapped into some "RHQ Monitoring" project that makes something coherent. And if we think charting, we should be able to show a particular metric along with events that happened during that time frame on a single chart.
It's possible that we endup merging those project ideas, but it's easier to merge than to split... But for sure, I want to extract RHQ into sub-projects that are easier to consume and test on their own.
For now, this is really just brainstorming, and as you can see only RHQ Metrics is concrete at this stage.
Please, keep sharing your thoughts, we need your feedback.
-
2. Re: Scoping, what's a metric or not?
genman Sep 8, 2014 5:32 PM (in response to theute)
And RHQ metrics -- at least any sort of UI you build on top of it -- really needs a way to map metrics to actual metric definitions (units, etc.), resources and groups and so will likely want to consume metadata from someplace. So you might want to have some sort of meta-data service as well. For serious use, permissions and security controls are probably something required as well and you'll need that.
Outside of monitoring Java apps I know log files are still a big deal in terms of monitoring, and something you should consider integration of second. It's something RHQ doesn't support well and could attract a lot of outside interest. If you can have RHQ monitor every log file (/var/log/*), discover both the application and its log file, and do whatever out of the box, supporting full text search and alerting similar to what Splunk does, you will have a winner. Splunk is very much hands on in terms of configuration, unfortunately.
-
3. Re: Re: Scoping, what's a metric or not?
pilhuhn Sep 16, 2014 11:52 AM (in response to theute)
This is a good discussion and I have the feeling that at least I am still biased by the historic RHQ setup (*1).
Classic RHQ
In RHQ
- metrics are (actively) collected at regular, fixed intervals. They may or may not me numeric (Numeric / Traits / Calltime)
- events are either asynchronously received (e.g. snmp traps) or written to a log file. They are treated as text.
- availability is (actively) collected regular, fixed intervals. We persist availability run length encoded whenever it changes.
We had already blurred the lines between those in the sense that Traits are collected at regular intervals, but only updated when they had changed. This makes them similar to Events. Only that the logic where the "create an update when something has changed" logic sits. Both times data is text.
Availability is internally stored as numbers in the table (so it could be a metric, *2) but is only updated when availability changes, like events.
Now
Now in RHQ-metrics (and the REST-api in RHQ) metrics are no longer necessarily collected at fixed intervals, but clients can push them whenever they want. Which makes them similar to events. If the value would be put into double quotes, those metrics would be events by above definition.
The major distinction is here is probably that numeric metrics can still be aggregated with min/avg/max to e.g. create monthly average values. Pure (textual) events do not allow such mathematical aggregations, but different ones like "how often does a certain message show in the log" or "how often did we receive a certain snmp trap".
The question is probably if we want to treat all of the above as <insert your favorite name, iyfn> and only define in metadata which aggregation (and other treatment) should take place on it. I guess that would also work for calltime data, which is like 2 dimensional events, where the url is the key and the payload is access time + perhaps status code; the aggregation would probably need to calculate the monthly average per url and status code instead of only per url.
*1 even if I was the one who introduced the REST api and the possibility to push metrics into RHQ
*2 some code even uses the same idea of schedules like for metrics to trigger availability collection
-
4. Re: Re: Scoping, what's a metric or not?
lkrejci Sep 16, 2014 2:26 PM (in response to pilhuhn)
The question of "calltime" data (a term I love to hate) is very interesting.
In the most abstract sense, calltime would be better called a "map" - just a set of key-value pairs.
What the calltime data, as implemented in RHQ, supports though is that it can, per key, send in an aggregated view of a set of values. I.e. when talking about "calltime" in RHQ sense, we're really talking about 2 different concepts:
1) Ability to handle "maps" or "histograms" as a valid input data
2) Ability to accept aggregates (over time) as valid input instead of a single value.
To illustrate the first point, a single metric collection could take a following form:
{"myMetric" : { "key1" : 1, "key2": 2, "key3": 3 } }
With the second point a single metric collection would look like:
{"myMetric" : { "from" : "2014-09-15 ..." , "to": "2014-09-16 ...", "min" : 0, "max" : 1000, "avg" : 15, "count" : 150 } }
where "from" and "to" define the time interval of the aggregated value, "min", "max" and "avg" are self-explanatory and "count" defines the total number of values that were used to produce this aggregate.
calltime in RHQ is the combination of both:
{"myMetric" : {"key1" : {"from" : "2014-09-15 ..." , "to": "2014-09-16 ...", "min" : 0, "max" : 1000, "avg" : 15, "count" : 150 }, "key2" : ... } }
The ability to handle the aggregated value as a valid input comes in handy when trying to for example correctly report invocation counts on EJB methods, etc. that ARE reported in such an aggregated manner - i.e. it is not possible to deduce an exact time and duration of a single EJB method call from Wfly management model - you always get a "historical overview" of the durations of the calls. This greatly reduces the memory requirements to store such stats on Wfly side.
The aggregated value offer a very interesting mathematics when trying to deal with potentially overlapping or disjoint time intervals of individual collections (which cannot be dismissed in a generic tool like rhq-metrics) and then answering questions like what was the value of the metric at certain time? The answer is a distribution of possible values, of course.
-
5. Re: Re: Scoping, what's a metric or not?
lkrejci Sep 16, 2014 4:16 PM (in response to lkrejci)
Look at how Netflix is doing metrics and calltime: Netflix/servo · GitHub
-
6. Re: Re: Scoping, what's a metric or not?
pilhuhn Sep 17, 2014 3:37 AM (in response to lkrejci)
What exactly in that one? The whole set of counters and gauges and so on looks a lot like Coda Hale Metrics to me, which is a library and setup used by many open source projects.
Still the gathering side for metrics is one part. The (server side) treatment a different beast. Do we want/need to really differentiate between numeric metrics, text documents and availability or are they basically all just a document, but with different metadata?
There is still one aspect that we did not look into yet and this is performance. If we'd store numeric metrics as String as opposed to Number, where would we end up?
-
7. Re: Re: Scoping, what's a metric or not?
theute Sep 17, 2014 4:03 AM (in response to genman)
Arf with the emails notifications being often broken, I missed your reply Elias...
Definitely the metadata about metrics is a must have.
I had conversations with Heiko about logs. My question at the moment is if we could treat log items as "events".
-
8. Re: Re: Scoping, what's a metric or not?
lkrejci Sep 17, 2014 4:25 AM (in response to pilhuhn)
I wanted to illustrate the fact the "calltime" or rather aggregate metrics are not a fixed term - there is a whole number of different stats that you can collect (from, to, min, max, count, avg, stddev, quantiles,...) and that they all have some aspects in common. I agree that servo is basically only a metric gathering framework, I'm not sure it contains any server-side logic. I just wanted to point out that maybe we should not try to port calltime as understood by RHQ now and instead come up with something more powerful. I.e. a way to reason about these more complex types of values on the server-side.
-
9. Re: Scoping, what's a metric or not?
john.sanda Sep 23, 2014 9:49 AM (in response to theute)
Thomas Heute wrote:
Those sub-projects would be wrapped into some "RHQ Monitoring" project that makes something coherent. And if we think charting, we should be able to show a particular metric along with events that happened during that time frame on a single chart.
It's possible that we endup merging those project ideas, but it's easier to merge than to split... But for sure, I want to extract RHQ into sub-projects that are easier to consume and test on their own.
In RHQ we wound up with a large, monolithic code base/project that is difficult to test and hard to reuse outside of RHQ. I am entirely in favor of starting with smaller sub-projects and merging them together if/when it seems appropriate. I also agree that it is easier to merge than split.
-
10. Re: Scoping, what's a metric or not?
pilhuhn Sep 24, 2014 9:05 AM (in response to john.sanda)
In RHQ we wound up with a large, monolithic code base/project that is difficult to test and hard to reuse outside of RHQ. I am entirely in favor of starting with smaller sub-projects and merging them together if/when it seems appropriate. I also agree that it is easier to merge than split.
I agree that we do not want to replicate the large code base into the new thingy. So the new thingy will not contain alerting. It will not contain inventory.
It will need to have a link somehow to security.
One project that can store three different things versus having 3 projects that all store a (different) "thing" may or may not be code bloat.
Can you please elaborate on the advantage of 2 or 3 projects for metrics / availability / events especially from the Cassandra point of view?
In understand that storing a number (double for metric or small int for availability ) vs a text (logfile entry) is different But is it different enough?
-
11. Re: Scoping, what's a metric or not?
theute Sep 25, 2014 7:55 AM (in response to genman)
Yes, we need to find the right balance, duplicating Cassandra integration in multiple projects would not make sense.
We need to define the types of content related to metrics/events/availability from a user point of view and how they differ (from a user point of view). They will differ for compaction.
- Metric (I don't like the name) -> Time, value, tags/annotations
- For compaction, we want to keep: min, max, avg
- Counters - Values that only go up -> Time, delta with previous value, tags/annotations
- For compaction we want to keep the total value at some points in time
- Throughput
- Binaries
- eg: availability
- "Events"
- Not collected at regular intervals
- May have some "large" payload (something to define the event like "Application XYZ got redeployed")
- Logs
- Store each log entry but in relation with other log entries (parent/child & previous/next)
Until we have a clear definition of each types and how they vary, it will be difficult to come up with a good granularity. My gut feeling is that we can and should store them all through the same project and they have some particularities that we can extract as metadata.
- Metric (I don't like the name) -> Time, value, tags/annotations
-
12. Re: Scoping, what's a metric or not?
pilhuhn Sep 29, 2014 3:36 AM (in response to theute)
I also think the duplication or worse triplication will do no good, as the code most likely (even with common libraries) will start to diverge in subtle ways.
For all the following we will probably need <id> and <timestamp on the sender> and optionally have a human readable name and description
"Metric" -- I also think this term is sort of overloaded. Especially with the current RHQ background. I think we need to define that as a numeric value at a certain point in time. Interesting question is if we want to differentiate between integer arithmetic vs floating point arithmetic values (i.e. allow to us long as opposed to double). We will need a
"Counter" -- what is the difference to a "Metric" that is marked as "trendsup"? I think the most important trait here is that for counters we want to (automatically?) compute a per time-unit derivate, as two points in time with 4000000 tx and later 4003200 does not really tell you anything, but 200 tx/s will.
"Throughput" -- I understand this as a "per time unit" value of a "Metric". Like that above mentioned derivate of the counter
"Binaries" - I think that binary only is relatively limited use. E.g. for Availability, we of course available and unavailable. And then there is "unknown". And for a group / an application there should perhaps also be "degraded" (ok, then it is no longer availability in the very basic sense, but more "health"). I would see this a a numeric metric, (internally) stored as a short integer with a mapping to "up","down", ... like an Enum in Java.
For the above, you see a log as a special "Event", that has linking to related items. Do we need that for some metrics too? Perhaps at Metadata level to enable it and then as a Mapped Diagnostic Context, MDC (http://logback.qos.ch/manual/mdc.html ) per item - actually that can be seen as a correlation id or tag, where log entries or also numeric metrics that logically belong together would get such an id. In fact that would be pretty cool for application performance.
Take this simple scenario
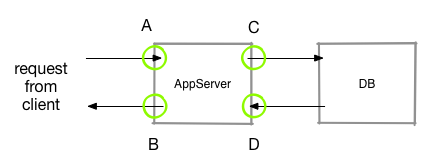
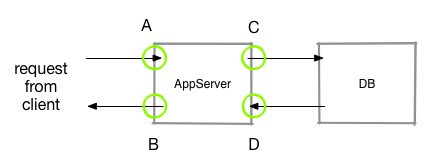
Here we could log something (event or numeric value) when a request is received at point A and then when the app starts retrieving data from the DB at point C. At D the DB call is back and at point B the request has finished processing.
(tB-tA) is then the full processing time which is divided into (tC-tA) for initial processing in the app, (tD-tC) DB access time and (tB-tD) as post processing in the app. This way if (tB-tA) gets too large, a user can drill into the other values to potentially better identify the bottlenecks.
Apache Camel and also RTGov seem to have such capabilities for their very specific use cases, which we could explore.
-
13. Re: Scoping, what's a metric or not?
heiko.braun Sep 29, 2014 8:01 AM (in response to pilhuhn)
this is a good discussion. i think that some of the ambiguity derives from lack of distinction between general concepts and data structures, as your recent post outlines. the data structures seem to be quiet similar for most cases and probably be collapsed into a single library/system. the concepts (product use cases) differ, and it seems we lack a term/concept for the fact that we different calculations on the same data structures. Like you described for "counter".
some thoughts on the "metric" types:
- i would propose to call "throughput" "rate". it seems to be a better fit IMO.
- "counter": as a counter i would expect an increasing/decreasing value by a single step (1). opposed to a general value that goes up and down, regardless of the steps.
- maybe call "binary" "condition"?
any suggestion for an alternative name for "metric"?
-
14. Re: Scoping, what's a metric or not?
john.sanda Sep 29, 2014 2:13 PM (in response to heiko.braun)
I agree that this a good, helpful discussion. We need to determine the various type of metrics and for the numeric types, determine what aggregate functions should be applied to them. I have also been thinking a bit about causality and correlation. Would it be useful to be able to specify causality and/or correlation relationships between metrics? Those relationships might in turn result in different and/or aggregation functions being applied.